Investigadores de la UPM han desarrollado un método basado en técnicas de aprendizaje automático para identificar signos de depresión a través del análisis de texto, brindando nuevas perspectivas en la detección temprana de esta afección
La depresión es una enfermedad mental común y debilitante que afecta a millones de personas, disminuyendo su calidad de vida y bienestar general. La creciente prevalencia de los trastornos de salud mental ha subrayado la necesidad de enfoques innovadores para detectar y abordar la depresión.
En este contexto, un equipo de investigadores de la Escuela Técnica Superior de Ingenieros de Telecomunicación (ETSIT) de la Universidad Politécnica de Madrid (UPM) ha avanzado significativamente en la detección temprana de signos de depresión, introduciendo un enfoque basado en aprendizaje automático que consigue resultados prometedores en la detección de depresión en texto.
Este enfoque no solo demuestra su eficacia en términos de rendimiento, sino que también se presenta como una solución práctica y accesible para la detección temprana de signos depresivos dentro del contenido digital.
El estudio, publicado en la revista internacional Applied Sciences, explora la eficacia de los métodos tradicionales de aprendizaje automático en la detección de la gravedad de los signos de depresión. Frente a modelos más complejos que demandan recursos computacionales significativos, el enfoque propuesto por investigadores del Grupo de Sistemas Inteligentes (GSI) de la UPM logra un equilibrio excelente entre rendimiento y eficiencia.
Para ello, se ha introducido en la investigación un marco de trabajo (framework) muy completo de características basadas en recursos léxicos. Este marco facilita la organización de las características textuales, integrando las señales lingüísticas, las expresiones emocionales y los patrones cognitivos para proporcionar una comprensión holística de los indicadores lingüísticos asociados a la depresión.
Para ello, se extrajeron un gran número de características y se organizaron en cuatro conjuntos: afectivas, temáticas, sociales y sintácticas. Los resultados sugieren que las características afectivas destacan en la clasificación de texto para la detección de depresión, pero la inclusión de características sociales, sintácticas y temáticas mejora el rendimiento de manera significativa.
La combinación de estas características con representaciones distribucionales, demuestra consistentemente un rendimiento superior en los conjuntos de datos donde se han evaluado.
La efectividad del enfoque propuesto se evalúa con un estudio experimental utilizando dos conjuntos de datos públicos en inglés de plataformas de redes sociales.
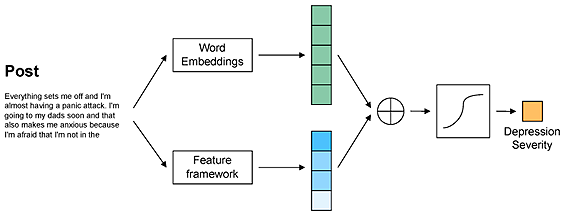
Representación general de la arquitectura del modelo propuesto.
Fuente: UPM. (Detection of the Severity Level of Depression Signs in Text Combining a Feature-Based Framework with Distributional Representations. Appl. Sci.2023, 13(21), 11695)
Como señala Sergio Muñoz, uno de los investigadores que ha formado parte del equipo de trabajo, “los hallazgos que hemos conseguido ofrecen una visión valiosa en la detección de la gravedad de la depresión en el texto. La capacidad de este enfoque para equilibrar rendimiento y recursos computacionales, junto con su interpretabilidad, allana el camino para avances significativos en la promoción de la salud mental y la intervención temprana”.
Aunque se reconocen limitaciones metodológicas, el estudio proporciona una base sólida para futuras investigaciones. Con la posibilidad de implementar esta tecnología en entornos reales, la UPM lidera la vanguardia en la creación de soluciones efectivas y accesibles para abordar los desafíos de la salud mental en nuestra sociedad.
Referencia bibliográfica: Sergio Muñoz y Carlos Á. Iglesias. Detection of the Severity Level of Depression Signs in Text Combining a Feature-Based Framework with Distributional Representations.
Appl. Sci.2023, 13(21), 11695; https://doi.org/10.3390/app132111695.
